 Как-то раз возник вопрос о поиске оптимальных алгоритмов при решении «классических задач в веб-разработках» с использованием PHP и MySQL.
Как-то раз возник вопрос о поиске оптимальных алгоритмов при решении «классических задач в веб-разработках» с использованием PHP и MySQL.
Предлагаю рассмотреть интересный пример…
Допустим, у нас есть таблица, в которой хранятся новости. Текстовые поля этой таблицы не важны для нашей задачи, поэтому мы создадим таблицу news всего с двумя полями: уникальным идентификатором новости и датой-временем добавления новости в формате unixtime.

Суть задачи такова: нужно сформировать массив годов/месяцев, "за которые были новости". Т.е. в массив не должны попасть те годы и/или месяцы, которым нет соответствия в поле n_dt таблицы news.
Например, массив должен выглядеть так:
- 2007
- 01
- 04
- 2008
- 02
Для начала рассмотрим два варианта решения этой задачи, принципиально отличающихся по своей сути.
Метод-1 (примитивный). Суть этого варианта сводится к тому, чтобы выбрать из БД все даты новостей, а затем проанализировать эти результаты "на стороне клиента", т.е. средствами того или иного языка программирования.
Рассмотрим пример кода на PHP…
$r=mysql_query("SELECT `n_dt` from `news` order by `n_dt` asc");
for ($i=0;$i<mysql_num_rows($r);$i++)
{
$d=mysql_result($r, $i, ‘n_dt’);
$year=date("Y", $d);
$month=date("m", $d);
$arr[$year][$month] =$month;
}
$t2=microtime(TRUE);
echo "<pre>";
print_r($arr);
echo "</pre>";
echo $t2-$t1;
Метод-2 (хитрый). Суть этого варианта сводится к тому, чтобы определить, за какие периоды были новости, не извлекая всю информацию из БД.
Сначала мы определим год самой старой и самой свежей новостей, а затем проверим каждый месяц всех годов в этом промежутке.
Рассмотрим пример кода на PHP…
$r=mysql_query("SELECT `n_dt` from `news` order by `n_dt` asc limit 1");
$start_year=date("Y", mysql_result($r, 0, ‘n_dt’));
$r=mysql_query("SELECT `n_dt` from `news` order by `n_dt` desc limit 1");
$stop_year=date("Y", mysql_result($r, 0, ‘n_dt’));
for ($i=$start_year; $i<=$stop_year; $i++)
{
for ($j=1; $j<=12; $j++)
{
$start_dt=mktime(1,1,1,$j,1,$i);
$stop_dt=mktime(1,1,1,$j+1,0,$i);
$r=mysql_query("SELECT COUNT(‘n_dt’) from `news`
where `n_dt`>=’$start_dt’ AND
`n_dt`<=’$stop_dt’");
if (mysql_result($r, 0, 0)>0)
{
$arr[$i][$j]=$j;
}
}
}
$t2=microtime(TRUE);
echo "<pre>";
print_r($arr);
echo "</pre>";
echo $t2-$t1;
Исследуем производительность этих двух алгоритмов при разном количестве данных.
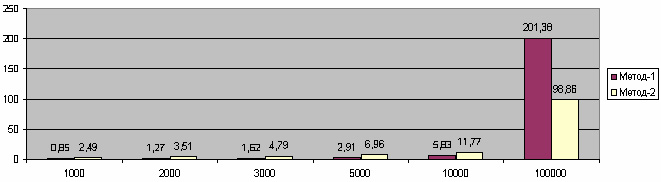
| Записей | Метод-1, с | Метод-2, с |
| 1000 | 0,85 | 2,49 |
| 2000 | 1,27 | 3,51 |
| 3000 | 1,62 | 4,79 |
| 5000 | 2,91 | 6,96 |
| 10000 | 5,83 | 11,77 |
| 100000 | 201,38 | 98,86 |
Метод-2, показывавший худшие результаты в начале теста (на малом количестве данных), обогнал конкурента на большом объёме данных почти в два раза.
При этом первый метод показывает достаточно сильное падение производительности.
Но можно ли как-то ещё больше ускорить решение этой задачи?
Можно.
Сейчас мы создадим индекс на поле, по которому происходит выборка (n_dt) и выполним тесты ещё раз.

Теперь статистика выглядит так (ОЧЕНЬ наглядно :)):
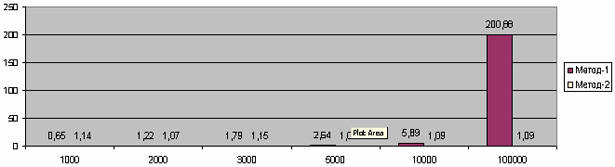
| Записей | Метод-1, с | Метод-2, с |
| 1000 | 0,65 | 1,14 |
| 2000 | 1,22 | 1,07 |
| 3000 | 1,79 | 1,15 |
| 5000 | 2,64 | 1,06 |
| 10000 | 5,89 | 1,09 |
| 100000 | 200,88 | 1,09 |
Фактически, производительность второго метода не зависит от количества данных. Да, при ОЧЕНЬ больших объемах данных (и, соответственно, больших индексах) его производительность тоже снизится, но всё равно он будет в сотни раз быстрее первого метода.
К слову, мы можем и дальше ускорять алгоритм решения этой задачи, оптимизируя логику формирования запроса.
А можно просто кэшировать результаты :).
К слову, эту же задачу можно решить и в случае, если в таблице данные о дате-времени хранятся в формате DATETIME.
Таблица будет иметь вид:

На поле n_dt сразу создадим индекс.
Мы можем применить только что рассмотренные нами методы ("примитивный" с обработкой данных на стороне клиента и "хитрый" с выборкой только части данных).
Рассмотрим исходный код…
Метод-1 ("примитивный"):
$r=mysql_query("SELECT YEAR(`n_dt`) as `Y`, MONTH(`n_dt`) as ‘M’
from `news2` order by `n_dt` asc");
for ($i=0;$i<mysql_num_rows($r);$i++)
{
$year=mysql_result($r, $i, ‘Y’);
$month=mysql_result($r, $i, ‘M’);
$arr[$year][$month]=$month;
}
$t2=microtime(TRUE);
echo "<pre>";
print_r($arr);
echo "</pre>";
echo $t2-$t1;
Метод-2 ("хитрый"):
$r=mysql_query("SELECT YEAR(`n_dt`) as `Y` from `news2`
order by `n_dt` asc limit 1");
$start_year=mysql_result($r, 0, ‘Y’);
$r=mysql_query("SELECT YEAR(`n_dt`) as `Y` from `news2`
order by `n_dt` desc limit 1");
$stop_year=mysql_result($r, 0, ‘Y’);
for ($i=$start_year; $i<=$stop_year; $i++)
{
for ($j=1; $j<=12; $j++)
{
$start_dt=$i."-".$j."-01 00:00:01";
$stop_dt=$i."-".($j+1)."-00 23:59:59";
$r=mysql_query("SELECT COUNT(‘n_dt’) from `news2`
where `n_dt`>=’$start_dt’
AND `n_dt`<=’$stop_dt’");
if (mysql_result($r, 0, 0)>0)
{
$arr[$i][$j]=$j;
}
}
}
$t2=microtime(TRUE);
echo "<pre>";
print_r($arr);
echo "</pre>";
echo $t2-$t1;
Но есть способ "заставить" MySQL при такой организации данных выдать информацию в уже агрегированном виде.
Придётся выполнить всего один запрос
order by MONTH(`n_dt`) asc SEPARATOR ‘, ‘) as `M` FROM `news2`
GROUP BY `Y`
Результат будет выглядеть так:
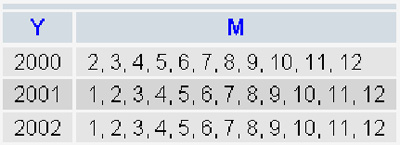
Теперь остаётся только разобрать средствами PHP данные из столбца `M` (столбец `Y` уже содержит готовые значения годов).
Рассмотрим исходный код…
Метод-3 ("оптимальный"):
$r=mysql_query("SELECT YEAR(`n_dt`) as `Y`,
GROUP_CONCAT(distinct MONTH(`n_dt`)
order by MONTH(`n_dt`) asc SEPARATOR ‘, ‘)
as `M` FROM `news2` GROUP BY `Y`");
for ($i=0;$i<mysql_num_rows($r);$i++)
{
$year=mysql_result($r, $i, "Y");
$m=mysql_result($r, $i, "M");
$month_arr=explode(",", $m);
foreach ($month_arr as $month_one)
{
$arr[$year][trim($month_one)]=trim($month_one);
}
}
$t2=microtime(TRUE);
echo "<pre>";
print_r($arr);
echo "</pre>";
echo $t2-$t1;
Проверка производительности на 100000 записях показывает следующее:
Метод-1: 230.16 с
Метод-2: 5.78 с
Метод-3: 0.5 с
А теперь – забавный эффект.
Если в первом методе заменить mysql_result() на mysql_fetch_assoc(), время работы метода составит 0.82 секунды вместо 230.16:
{
$year=$x[‘Y’];
$month=$x[‘M’];
$arr[$year][$month]=$month;
}
Метод-3 оказывается самым оптимальным в том плане, что позволяет MySQL максимально использовать возможности оптимизации запросов, а также требует минимума памяти на стороне клиента, в то время как метод-1 при больших объёмах данных приводит к риску превысить объём доступной скрипту оперативной памяти.
Также обратите внимание на то, что метод-2 оказывается неоптимальным в силу того факта, что в нём приходится выполнять много запросов.
Выигрыш в производительности при уменьшении количества запросов иллюстрирует следующий пример. Для решения данной задачи использовался скрипт, заполняющий БД данными.
Метод-1 основан на выполнении одного запроса на вставку каждой записи.
Метод-2 основан на формировании одного запроса на вставку 1000 записей.
При вставке 1000 записей время работы скриптов таково (исходники – на следующих слайдах).
Метод-1: 16.04 с
Метод-2: 0.16 с
Метод-1 (не оптимальный):
for ($i=0;$i<1000;$i++)
{
$dt=rand(0,2000000000);
mysql_query("INSERT into `news` (`n_dt`) values (‘$dt’)");
}
$t2=microtime(TRUE);
echo $t2-$t1;
Метод-2 (оптимальный):
$query="INSERT into `news` (`n_dt`) values ";
for ($i=0;$i<1000;$i++)
{
$dt=rand(0,2000000000);
$query.="(‘$dt’), ";
}
$query=substr($query,0,strlen($query)-2);
mysql_query($query);
$t2=microtime(TRUE);
echo $t2-$t1;
Общий вывод: решение любой задачи можно воплотить в жизнь самыми разными способами. Грамотное совмещение оптимизации на стороне клиента и сервера позволяет достичь действительно высокой производительности даже на достаточно больших объёмах данных.